Spark RDD Dependence
Dependencies
Narrow Dependencies
- 任何一個Parent RDD的Partition至多被Child RDD的某個Partition使用一次
- 有些可能沒用被使用
- 透過流水線(pipelining possible)的方式進行傳遞
- 不存在shuffle
- 如果某個Partition遺失了,可以快速使用Parent RDD對應的Patition計算出來,容錯與計算速度都很快
Wide Dependencies:
- 任何一個Parent RDD的Partition會被Child RDD的partition使用多次
- 有些可能沒用被使用
- 會產生Shuffle
- 一遇到Shuffle,就會將Job分割成2個Stage
- Shuffle可能造成部分或者全部的Data需要進行網路傳輸
- 因為會產生Shuffle,所以可能有數據傾斜的情況
- 若Partition遺失了,則需要計算所有相關父RDD的資料,相較於Narrow dependencies,其容錯速度較低
Dependencies and Lineage Concept

- Dependencies Concept
- RDD0到RDD1之間是Narrow dependencies,例如進行map操作
- RDD1到RDD2和RDD3之間是Wide dependencies,例如進行reduceByKey操作
- Lineage Concept
- 對RDD1進行cache操作,因此在計算RDD2與RDD3時,可以直接從記憶體中直接拿取RDD1的資訊
- 若RDD1中的Partition3丟失了,則在計算RDD2與RDD3時,會自動到RDD0中的Partition3進行重新計算得到RDD1的Partition3,而RDD1中其他的Partition不受影響
Transformations
- 可能產生Narrow dependencies的Transformations
- map
- mapValues
- flatMap
- filter
- mapPartitions
- mapPartitionsWithIndex
- 可能產生Wide dependencies的Transformations(可能造成Shuffle)
- cogroup
- groupWith
- join
- leftOuterJoin
- rightOuterJoin
- groupByKey
- reduceByKey
- combineByKey
- distinct
- intersection
- repartition
- coalesce
Dependency Objects
RDD在使用dependencies方法時,會回傳一個由List表示的Dependency object,而不同類型的RDD會回傳不同的Dependency object
Dependency object可以根據dependency分成兩類:
- Narrow dependency objects
- OneToOneDependency
- PruneDependency
- RangeDependency
- Wide dependency objects
- ShuffleDependency
- 相關程式位置為org.apache.spark.rdd的RDD.scala
|
|
Wordcount Demo
這裡使用Spark wordcount例子,圖形化說明在每個步驟的RDD及其Patitions的狀態,以及RDD之間的Dependency關係
Sacla程式如下:

- 上圖描述wordcount整個流程的執行過程,並分別用使用Scala中的變量對應每個步驟的過程
- 當中flatMap與map皆為Narrow dependence
- reduceByKey為Wide dependence,故產生了Shuffle,並將Job切割成2個Stage
Spark Shell Demo
下面使用Spark shell執行wordcount
DAG
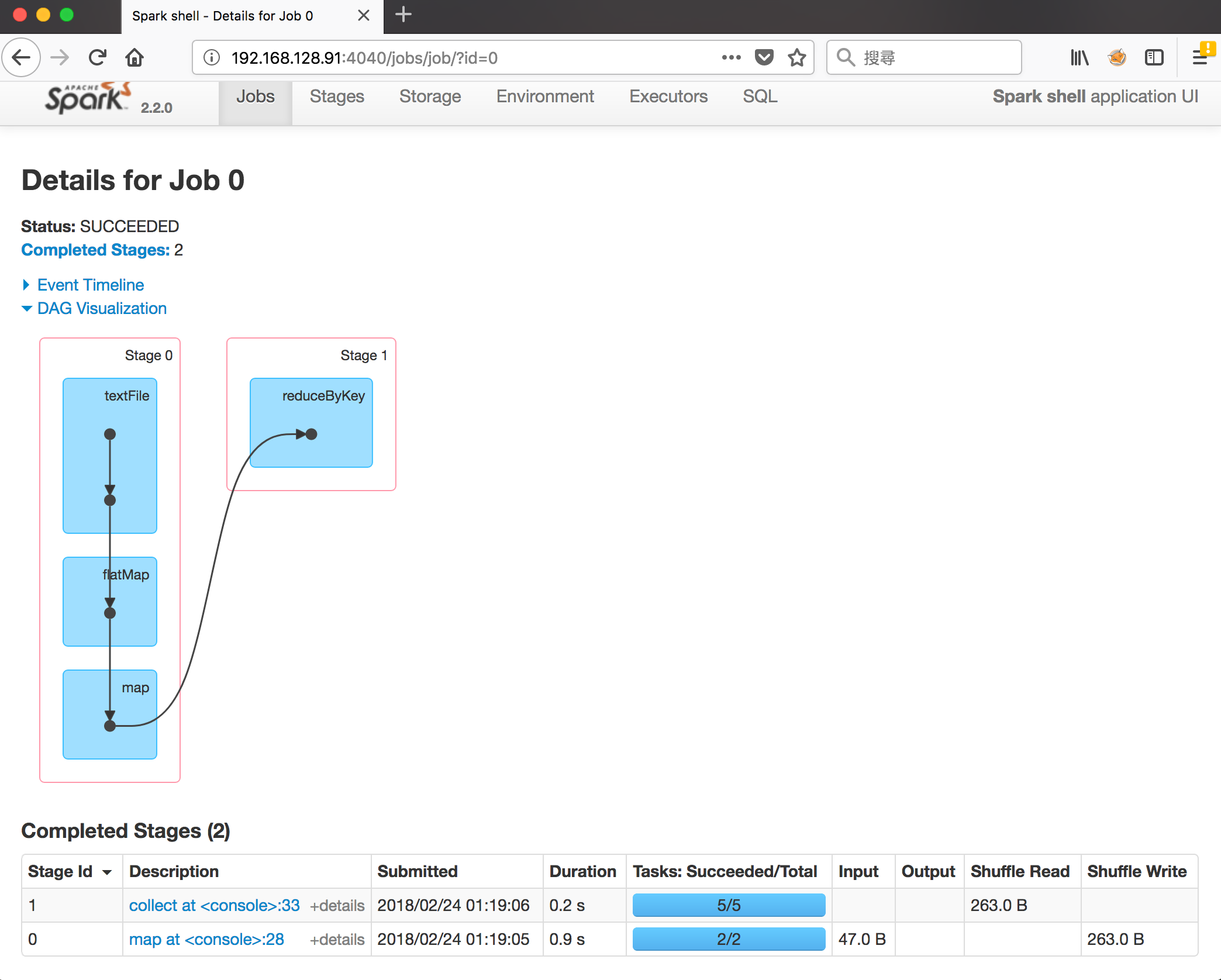
- 與Wordcount Demo部分的圖相呼應,reduceByKey造成了Shuffle,故分割成2個Stage
- Completed Stages中,Stage id為0的Tasks為2,是因為textFile預設為2個Partition,而Partition數量與Task對應
- Stage id為1的Tasks為5,是因為reduceByKey的第二個參數指定為輸出5個Partition
Dependency Objects and Lineage
- 使用dependencies方法得知該RDD的Dependency object
- 使用toDebugString方法得知該RDD的Lineage以及RDD object,在DAG圖上也會顯示RDD object的訊息
- 根據Dependency object或RDD object可以得知Transformation的Dependency類別(Narrow or Wide),以及是否會產生Shuffle1234567891011121314151617181920212223242526272829scala> words.dependenciesres1: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.OneToOneDependency@79799b21)scala> pairs.dependenciesres2: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.OneToOneDependency@6eedbb7b)scala> wordcount.dependenciesres3: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.ShuffleDependency@43c0b11a)scala> words.toDebugStringres4: String =(2) MapPartitionsRDD[2] at flatMap at <console>:26 []| file:////home/hadoop/testFile MapPartitionsRDD[1] at textFile at <console>:24 []| file:////home/hadoop/testFile HadoopRDD[0] at textFile at <console>:24 []scala> pairs.toDebugStringres5: String =(2) MapPartitionsRDD[3] at map at <console>:28 []| MapPartitionsRDD[2] at flatMap at <console>:26 []| file:////home/hadoop/testFile MapPartitionsRDD[1] at textFile at <console>:24 []| file:////home/hadoop/testFile HadoopRDD[0] at textFile at <console>:24 []scala> wordcount.toDebugStringres6: String =(5) ShuffledRDD[4] at reduceByKey at <console>:30 []+-(2) MapPartitionsRDD[3] at map at <console>:28 []| MapPartitionsRDD[2] at flatMap at <console>:26 []| file:////home/hadoop/testFile MapPartitionsRDD[1] at textFile at <console>:24 []| file:////home/hadoop/testFile HadoopRDD[0] at textFile at <console>:24 []