Flink Execution Graph
延續上篇Job Graph產生,此篇說明Execution Graph生成的過程與目的
Client Submit Job Graph
在ClusterClient的程序中,取得JobGraph後,會呼叫其實現類RestClusterClient<T>的submitJob(…),在此方法中會透過HTTP POST的方式將JobGraph提交給Dispatcher
ClusterClient @org/apache/flink/client/program/ClusterClient.java
RestClusterClient @org/apache/flink/client/program/rest/RestClusterClient.java
Start Standalone Cluster
這裡須先說明Standalone的Dispatcher是如何執行的,以及其入口類
在啟動Standalone mode時,是透過start-cluster.sh啟動,透過jobmanager.sh最終調用flink-daemon.sh,並使用org.apache.flink.runtime.entrypoint.StandaloneSessionClusterEntrypoint作為入口類,將Standalone Cluster啟動
|
|
進入ClusterEntrypoint.runClusterEntrypoint(…)後,會走到ClusterEntrypoint的runCluster(…),此時會透過實現類StandaloneSessionClusterEntrypoint的createDispatcherResourceManagerComponentFactory(…),取得dispatcherResourceManagerComponentFactory,故dispatcherResourceManagerComponentFactory為SessionDispatcherResourceManagerComponentFactory object。
接著透過dispatcherResourceManagerComponentFactory.create(…),在SessionDispatcherResourceManagerComponentFactory的父類AbstractDispatcherResourceManagerComponentFactory會初始化Dispatcher REST endpoint、Resource Manager,Dispatcher,等待Client端提交Flink job
|
|
Receive Client Request
根據FLIP-6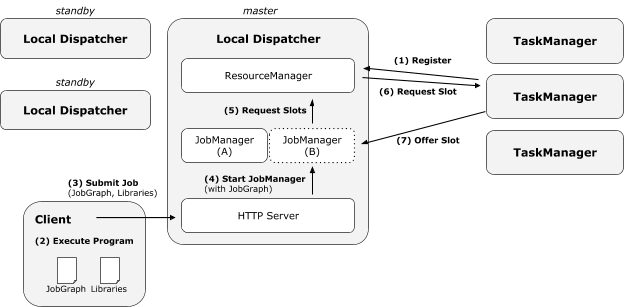
透過HTTP上傳至Dispatcher @StandaloneDispatcher的父類Dispatcher
|
|
Dispatcher會啟動JobMaster,JobMaster會開始Build ExecutionGraph
|
|
Build Execution Graph
ExecutionGraphBuilder.buildGraph(…)當中Execution Graph的建立流程在attachJobGraph function中,主要分成2個步驟
- new ExecutionJobVertex(…) @org/apache/flink/runtime/executiongraph/ExecutionJobVertex.java
- 將已排序的
JobVertex拓墣,建立對應的ExecutionJobVertex- 拓墣保證如果在節點A->B中存在有向邊,那麼排序後節點A肯定在B之前
- 一個
JobVertex對應一個ExecutionJobVertex
- 創建N個
IntermediateResult- N為對應的
JobVertex中IntermediateDataSet的數量 - 每一個
IntermediateResult都有parallelism個生產者,對應parallelism個IntermediateResultPartition
- N為對應的
- 創造M個
ExecutionVertex- M為對應的parallelism
ExecutionEdge是其的輸入,IntermediateResultPartition是其的輸出IntermediateResultPartition表示ExecutionVertex的一個輸出分區
- 將已排序的
- ejv.connectToPredecessors(this.intermediateResults)
- 將
ExecutionJobVertex的上下游關西建立,並將其連接 - 每一個
ExecutionJobVertex都會和上游的IntermediateResult建立連接,生成ExecutionEdge
- 將
參考官方文檔說明JobManager轉換Job Graph到Execution Graph的過程
|
|
Summarry
- ExecutionGraph是JobGraph的並行化版本,是調度層最核心的數據結構
- ExecutionGraph代表運行時的執行計畫,包括Task並行、連接、中間結果的維護