Compere Alluxio with HDFS
Purpose
- 在Hadoop上,對Alluxio與HDFS中的文件進行操作,比較其讀入的數據量和執行速度。
- 在Spark上,對Alluxio與HDFS中的文件進行操作,比較其讀入的數據量和執行速度。
Prepare for Testing File
|
|
Hadoop Testing
- 使用Hadoop自帶的測試包中的wordcount,並分別讀取Alluxio與HDFS中的文件,進行測試。123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145146147148149150151152153154155156157158159160161162163164165166167168169170171172173174175176177178179180181182183184185186187188# 對Alluxio中的文件進行測試[hadoop@testmain ~]$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.1.jar wordcount -libjars $ALLUXIO_HOME/client/hadoop/alluxio-1.6.0-hadoop-client.jar alluxio://localhost:19998/wordcount/input/page_views.dat alluxio://localhost:19998/wordcount/output# ...17/11/08 01:24:17 INFO mapreduce.Job: map 0% reduce 0%17/11/08 01:24:19 INFO mapred.LocalJobRunner:17/11/08 01:24:19 INFO mapred.MapTask: Starting flush of map output17/11/08 01:24:19 INFO mapred.MapTask: Spilling map output17/11/08 01:24:19 INFO mapred.MapTask: bufstart = 0; bufend = 22090342; bufvoid = 10485760017/11/08 01:24:19 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 23122784(92491136); length = 3091613/655360017/11/08 01:24:21 INFO mapred.MapTask: Finished spill 017/11/08 01:24:21 INFO mapred.Task: Task:attempt_local1066655942_0001_m_000000_0 is done. And is in the process of committing17/11/08 01:24:21 INFO mapred.LocalJobRunner: map17/11/08 01:24:21 INFO mapred.Task: Task 'attempt_local1066655942_0001_m_000000_0' done.17/11/08 01:24:21 INFO mapred.LocalJobRunner: Finishing task: attempt_local1066655942_0001_m_000000_017/11/08 01:24:21 INFO mapred.LocalJobRunner: map task executor complete.17/11/08 01:24:21 INFO mapred.LocalJobRunner: Waiting for reduce tasks17/11/08 01:24:21 INFO mapred.LocalJobRunner: Starting task: attempt_local1066655942_0001_r_000000_017/11/08 01:24:21 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 117/11/08 01:24:21 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false17/11/08 01:24:21 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]17/11/08 01:24:21 INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@7df3efe217/11/08 01:24:21 INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=363285696, maxSingleShuffleLimit=90821424, mergeThreshold=239768576, ioSortFactor=10, memToMemMergeOutputsThreshold=1017/11/08 01:24:21 INFO reduce.EventFetcher: attempt_local1066655942_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events17/11/08 01:24:21 INFO mapreduce.Job: map 100% reduce 0%17/11/08 01:24:21 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local1066655942_0001_m_000000_0 decomp: 7915818 len: 7915822 to MEMORY17/11/08 01:24:21 INFO reduce.InMemoryMapOutput: Read 7915818 bytes from map-output for attempt_local1066655942_0001_m_000000_017/11/08 01:24:21 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 7915818, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->791581817/11/08 01:24:21 INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning17/11/08 01:24:21 INFO mapred.LocalJobRunner: 1 / 1 copied.17/11/08 01:24:21 INFO reduce.MergeManagerImpl: finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs17/11/08 01:24:21 INFO mapred.Merger: Merging 1 sorted segments17/11/08 01:24:21 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 7915768 bytes17/11/08 01:24:22 INFO reduce.MergeManagerImpl: Merged 1 segments, 7915818 bytes to disk to satisfy reduce memory limit17/11/08 01:24:22 INFO reduce.MergeManagerImpl: Merging 1 files, 7915822 bytes from disk17/11/08 01:24:22 INFO reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce17/11/08 01:24:22 INFO mapred.Merger: Merging 1 sorted segments17/11/08 01:24:22 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 7915768 bytes17/11/08 01:24:22 INFO mapred.LocalJobRunner: 1 / 1 copied.17/11/08 01:24:22 INFO Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords17/11/08 01:24:23 INFO mapred.Task: Task:attempt_local1066655942_0001_r_000000_0 is done. And is in the process of committing17/11/08 01:24:23 INFO mapred.LocalJobRunner: 1 / 1 copied.17/11/08 01:24:23 INFO mapred.Task: Task attempt_local1066655942_0001_r_000000_0 is allowed to commit now17/11/08 01:24:23 INFO output.FileOutputCommitter: Saved output of task 'attempt_local1066655942_0001_r_000000_0' to alluxio://localhost:19998/wordcount/output/_temporary/0/task_local1066655942_0001_r_00000017/11/08 01:24:23 INFO mapred.LocalJobRunner: reduce > reduce17/11/08 01:24:23 INFO mapred.Task: Task 'attempt_local1066655942_0001_r_000000_0' done.17/11/08 01:24:23 INFO mapred.LocalJobRunner: Finishing task: attempt_local1066655942_0001_r_000000_017/11/08 01:24:23 INFO mapred.LocalJobRunner: reduce task executor complete.17/11/08 01:24:24 INFO mapreduce.Job: map 100% reduce 100%17/11/08 01:24:24 INFO mapreduce.Job: Job job_local1066655942_0001 completed successfully17/11/08 01:24:24 INFO mapreduce.Job: Counters: 40File System CountersALLUXIO: Number of bytes read=38029986ALLUXIO: Number of bytes written=7281357ALLUXIO: Number of read operations=13ALLUXIO: Number of large read operations=0ALLUXIO: Number of write operations=4FILE: Number of bytes read=52010784FILE: Number of bytes written=60859072FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=0HDFS: Number of bytes written=0HDFS: Number of read operations=0HDFS: Number of large read operations=0HDFS: Number of write operations=0Map-Reduce FrameworkMap input records=100000Map output records=772904Map output bytes=22090342Map output materialized bytes=7915822Input split bytes=121Combine input records=772904Combine output records=157240Reduce input groups=157240Reduce shuffle bytes=7915822Reduce input records=157240Reduce output records=157240Spilled Records=314480Shuffled Maps =1Failed Shuffles=0Merged Map outputs=1GC time elapsed (ms)=85Total committed heap usage (bytes)=331489280Shuffle ErrorsBAD_ID=0CONNECTION=0IO_ERROR=0WRONG_LENGTH=0WRONG_MAP=0WRONG_REDUCE=0File Input Format CountersBytes Read=19014993File Output Format CountersBytes Written=728135717/11/08 01:24:24 INFO connection.NettyChannelPool: Channel closed# 對HDFS中的文件進行測試[hadoop@testmain ~]$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.1.jar wordcount hdfs://192.168.128.91:9000/wordcount/input/page_views.dat hdfs://192.168.128.91:9000/wordcount/output# ...17/11/08 01:25:08 INFO mapreduce.Job: map 0% reduce 0%17/11/08 01:25:09 INFO mapred.LocalJobRunner:17/11/08 01:25:09 INFO mapred.MapTask: Starting flush of map output17/11/08 01:25:09 INFO mapred.MapTask: Spilling map output17/11/08 01:25:09 INFO mapred.MapTask: bufstart = 0; bufend = 22090342; bufvoid = 10485760017/11/08 01:25:09 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 23122784(92491136); length = 3091613/655360017/11/08 01:25:11 INFO mapred.MapTask: Finished spill 017/11/08 01:25:11 INFO mapred.Task: Task:attempt_local556577714_0001_m_000000_0 is done. And is in the process of committing17/11/08 01:25:11 INFO mapred.LocalJobRunner: map17/11/08 01:25:11 INFO mapred.Task: Task 'attempt_local556577714_0001_m_000000_0' done.17/11/08 01:25:11 INFO mapred.LocalJobRunner: Finishing task: attempt_local556577714_0001_m_000000_017/11/08 01:25:11 INFO mapred.LocalJobRunner: map task executor complete.17/11/08 01:25:11 INFO mapred.LocalJobRunner: Waiting for reduce tasks17/11/08 01:25:11 INFO mapred.LocalJobRunner: Starting task: attempt_local556577714_0001_r_000000_017/11/08 01:25:11 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 117/11/08 01:25:11 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false17/11/08 01:25:11 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]17/11/08 01:25:11 INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@38c3269417/11/08 01:25:11 INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=363285696, maxSingleShuffleLimit=90821424, mergeThreshold=239768576, ioSortFactor=10, memToMemMergeOutputsThreshold=1017/11/08 01:25:11 INFO reduce.EventFetcher: attempt_local556577714_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events17/11/08 01:25:11 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local556577714_0001_m_000000_0 decomp: 7915818 len: 7915822 to MEMORY17/11/08 01:25:11 INFO reduce.InMemoryMapOutput: Read 7915818 bytes from map-output for attempt_local556577714_0001_m_000000_017/11/08 01:25:11 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 7915818, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->791581817/11/08 01:25:11 INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning17/11/08 01:25:11 INFO mapred.LocalJobRunner: 1 / 1 copied.17/11/08 01:25:11 INFO reduce.MergeManagerImpl: finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs17/11/08 01:25:11 INFO mapred.Merger: Merging 1 sorted segments17/11/08 01:25:11 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 7915768 bytes17/11/08 01:25:11 INFO reduce.MergeManagerImpl: Merged 1 segments, 7915818 bytes to disk to satisfy reduce memory limit17/11/08 01:25:11 INFO reduce.MergeManagerImpl: Merging 1 files, 7915822 bytes from disk17/11/08 01:25:11 INFO reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce17/11/08 01:25:11 INFO mapred.Merger: Merging 1 sorted segments17/11/08 01:25:11 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 7915768 bytes17/11/08 01:25:11 INFO mapred.LocalJobRunner: 1 / 1 copied.17/11/08 01:25:11 INFO Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords17/11/08 01:25:11 INFO mapreduce.Job: map 100% reduce 0%17/11/08 01:25:12 INFO mapred.Task: Task:attempt_local556577714_0001_r_000000_0 is done. And is in the process of committing17/11/08 01:25:12 INFO mapred.LocalJobRunner: 1 / 1 copied.17/11/08 01:25:12 INFO mapred.Task: Task attempt_local556577714_0001_r_000000_0 is allowed to commit now17/11/08 01:25:12 INFO output.FileOutputCommitter: Saved output of task 'attempt_local556577714_0001_r_000000_0' to hdfs://192.168.128.91:9000/wordcount/output/_temporary/0/task_local556577714_0001_r_00000017/11/08 01:25:12 INFO mapred.LocalJobRunner: reduce > reduce17/11/08 01:25:12 INFO mapred.Task: Task 'attempt_local556577714_0001_r_000000_0' done.17/11/08 01:25:12 INFO mapred.LocalJobRunner: Finishing task: attempt_local556577714_0001_r_000000_017/11/08 01:25:12 INFO mapred.LocalJobRunner: reduce task executor complete.17/11/08 01:25:12 INFO mapreduce.Job: map 100% reduce 100%17/11/08 01:25:12 INFO mapreduce.Job: Job job_local556577714_0001 completed successfully17/11/08 01:25:12 INFO mapreduce.Job: Counters: 35File System CountersFILE: Number of bytes read=16435224FILE: Number of bytes written=24996682FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=38029986HDFS: Number of bytes written=7281357HDFS: Number of read operations=13HDFS: Number of large read operations=0HDFS: Number of write operations=4Map-Reduce FrameworkMap input records=100000Map output records=772904Map output bytes=22090342Map output materialized bytes=7915822Input split bytes=122Combine input records=772904Combine output records=157240Reduce input groups=157240Reduce shuffle bytes=7915822Reduce input records=157240Reduce output records=157240Spilled Records=314480Shuffled Maps =1Failed Shuffles=0Merged Map outputs=1GC time elapsed (ms)=69Total committed heap usage (bytes)=331489280Shuffle ErrorsBAD_ID=0CONNECTION=0IO_ERROR=0WRONG_LENGTH=0WRONG_MAP=0WRONG_REDUCE=0File Input Format CountersBytes Read=19014993File Output Format CountersBytes Written=7281357
Spark Testing
使用Spark shell執行wordcount,並分別讀取Alluxio與HDFS中的文件,進行測試。
1234567891011121314151617181920212223242526272829# 刪除Alluxio與Hdfs的輸出文件,避免在此步驟出現錯誤[hadoop@testmain ~]$ alluxio fs rm -R /wordcount/output/wordcount/output has been removed[hadoop@testmain ~]$ hdfs dfs -rm -r /wordcount/outputDeleted /wordcount/output# 執行Spark shell[hadoop@testmain ~]$ spark-shell --master local[2]Spark context Web UI available at http://192.168.128.91:4040# ...# 對Alluxio中的文件進行測試scala> val textFile = sc.textFile("alluxio://192.168.128.91:19998/wordcount/input/page_views.dat")textFile: org.apache.spark.rdd.RDD[String] = alluxio://192.168.128.91:19998/wordcount/input/page_views.dat MapPartitionsRDD[1] at textFile at <console>:24scala> val counts = textFile.flatMap(line => line.split("\t")).map(word => (word, 1)).reduceByKey(_ + _)counts: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:26scala> counts.saveAsTextFile("alluxio://192.168.128.91:19998/wordcount/output/spark_alluxio.output")# 對HDFS中的文件進行測試scala> val textFile = sc.textFile("hdfs://192.168.128.91:9000/wordcount/input/page_views.dat")textFile: org.apache.spark.rdd.RDD[String] = hdfs://192.168.128.91:9000/wordcount/input/page_views.dat MapPartitionsRDD[7] at textFile at <console>:24scala> val counts = textFile.flatMap(line => line.split("\t")).map(word => (word, 1)).reduceByKey(_ + _)counts: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[10] at reduceByKey at <console>:26scala> counts.saveAsTextFile("hdfs://192.168.128.91:9000/wordcount/output/spark_alluxio.output")Alluxio result
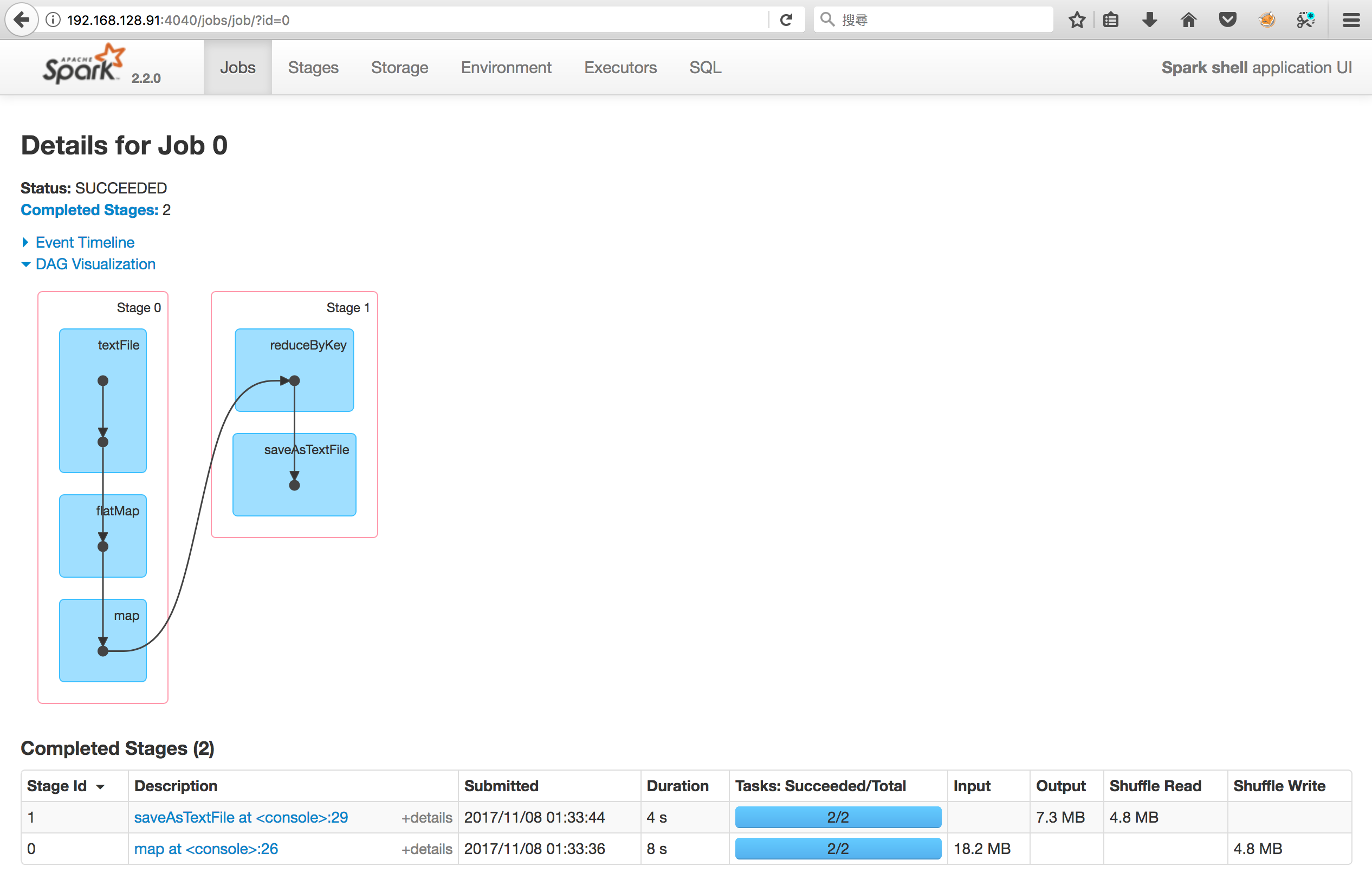
- Hdfs result
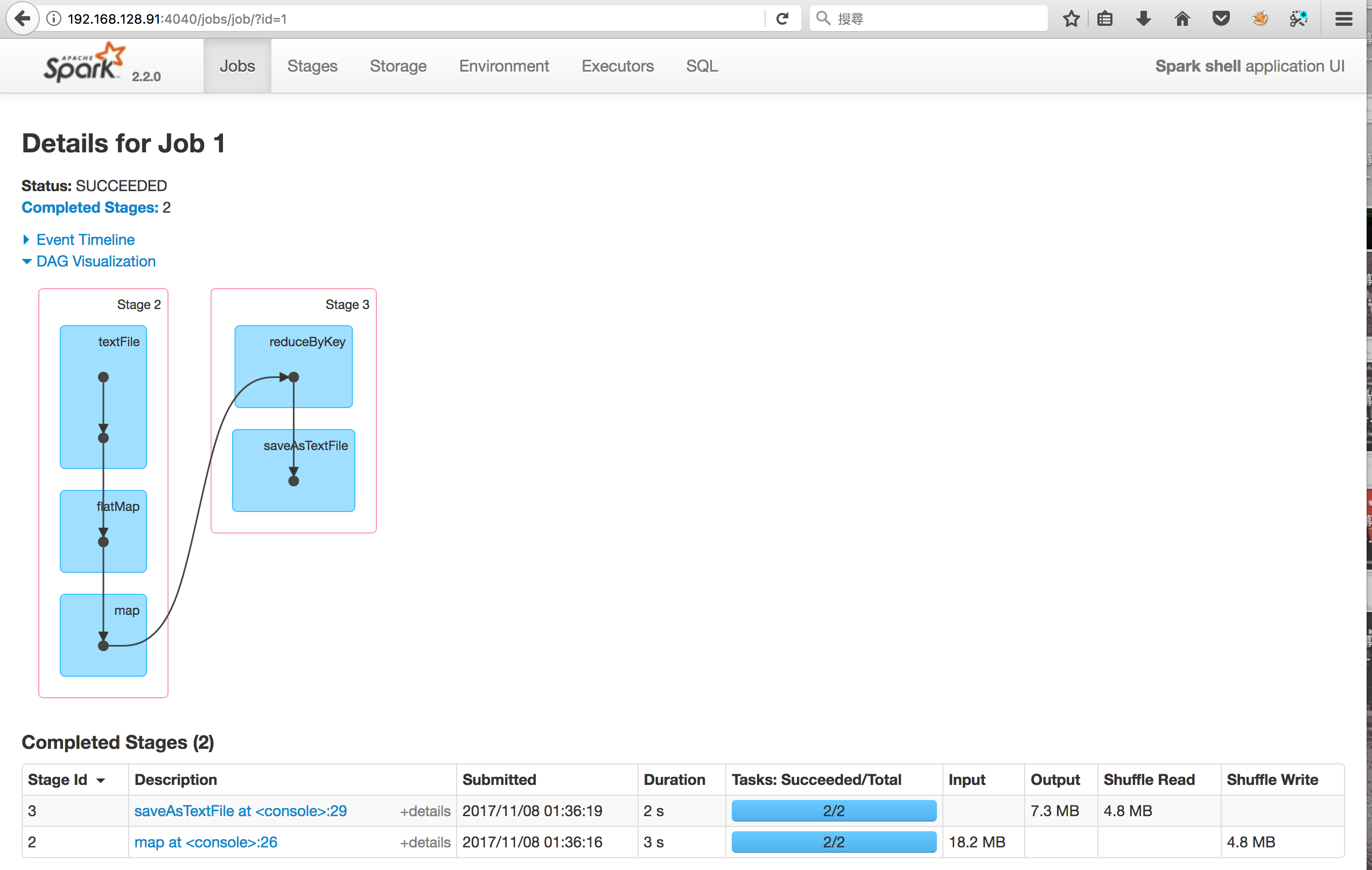
Summary
- 在小文件的作業上,Alluxio的讀入數據量與HDFS相同;在執行速度上,HDFS較優
| Platform | Input of Alluxio | Input of HDFS | Duration of Alluxio | Duration of HDFS |
|---|---|---|---|---|
| Hadoop | 18.2MB | 18.2MB | 7s | 4s |
| Spark | 18.2MB | 18.2MB | 12s | 5s |